tl;dr: handling event ordering correctly in distributed systems is tricky. In this post I cover 7 approaches to coping with concurrency.
Robust distributed systems are notoriously difficult to build. The difficulty arises from two properties in particular:
-
Limited knowledge: each node knows its own state, and it knows what state the other nodes were in recently, but it can’t know their current state.
-
(Partial) failures: individual nodes can fail at any time, and the network can delay or drop messages arbitrarily.
Why are these properties difficult to grapple with? Suppose you’re writing code for a single node. You’re deep in a nested conditional statement, and you need to deal with a message arrival. How do you react? What if the message you’re seeing was actually delayed by the network and is no longer relevant? What if some of the nodes you need to coordinate with have failed, but you aren’t aware of it yet? The set of possible event sequences you need to reason about is huge, and it’s all too easy to forget about the one nasty corner case that will eventually bring your system to a screeching halt.
To make the discussion more concrete, let’s look at an example.
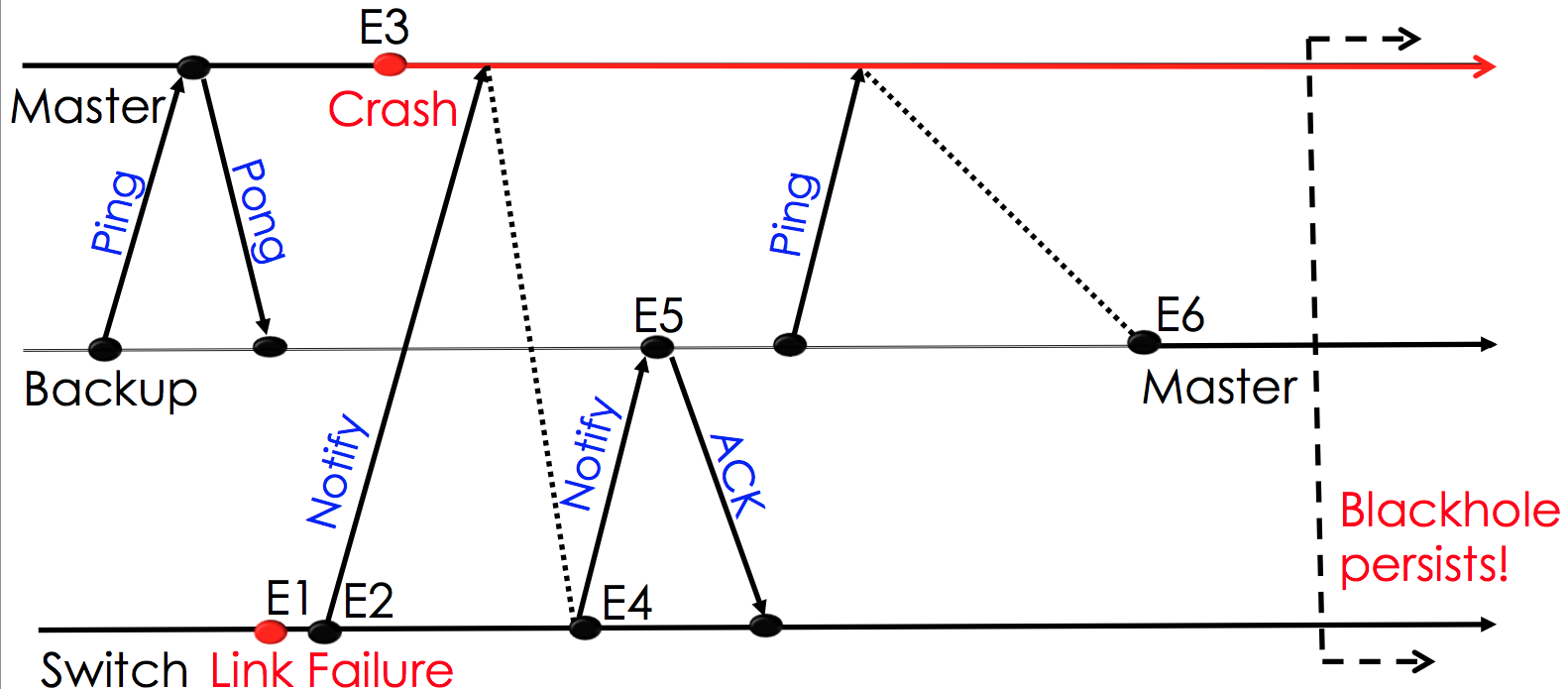
The figure above depicts a race condition [1] in Floodlight, a distributed controller for software-defined networks. With Floodlight, switches maintain one hot connection to a master controller and one or more cold connections to replica controllers. The master holds the authority to modify the configuration of the switches, while the other controllers are in slave mode and do not perform any changes to the switch configurations unless they detect that the master has crashed [2].
The race condition is triggered when a link fails (E1), and the switch attempts to notify the controllers (E2,E4) shortly after the master has died (E3), but before a new master has been selected (E6). In this case, all live controllers are in the slave role and will not take responsibility for updating the switch flow table (E5). At some point, heartbeat messages time out and one of the slaves elevates itself to the master role (E6). The new master will proceed to manage the switch, but without ever clearing the routing entries for the failed link (resulting in a persistent blackhole) [3].
If we take a step back, we see that there are two problems involved: leader election (“Who is the master at any point in time?”), and replication (“How should the backups behave?”). Let’s assume that leader election is handled by a separate consensus algorithm (e.g. Paxos), and focus our attention on replication.
Now that we have a concrete example to think about, let’s go over a few solutions this problem. The first four share the same philosophy: “get the ordering right”.
Take it case-by-case
The straightforward fix here is to add a conditional statement for this event ordering: if you’re a slave, and the next message is a link failure notification, store the notification in memory in case you become master later.
This fix seems easy in retrospect. But recall how the bug came about in the first place: the programmer had some set of event orderings in mind when writing the code, but didn’t implement one corner case. How do we know there isn’t another race condition lurking somewhere else in the code? [4]
The number of event orderings you need to consider in a distributed system is truly huge; it scales combinatorially with the number of nodes you’re communicating with. For the rest of this post, let’s see if we can avoid the need to reason on a case-by-case basis altogether.
Replicate the computation
Consider a system consisting of only one node. In this world, there is a single, global order (with no race conditions)!
How can we obtain a global event order, yet still achieve fault tolerance? One way [5] is to have the backup nodes mimic every step of the master node: forward all inputs to the master, have the master choose a serial order for those events, issue the appriopriate commands to the switches, and replicate the decision to the backups [6]. The key here is that each backup should execute the computation in the exact same order as the master.
For the Floodlight bug, the backup would still need to hold the link failure message in memory until it detects that the master has crashed. But we’ve gained a powerful guarantee over the previous approach: when the backup takes over for the master, it will be in a up-to-date state, and know exactly what commands it needs to send to the switches to get them into a correct configuration.
Make your event handlers transactional
Transactions allow us to make a group of operations appear either as if they happened simultaneously, or not at all. This is a powerful idea!
How could transactions help us here? Suppose we did the following: whenever a message arrives, find the event handler for that message, wrap it in a transaction, run the event handler, and hand the result of the transaction to the master controller. The master decides on a global order, checks whether any concurrent transactions conflict with each other (and aborts one of them if they do), updates the switches, sends the serialized transactions to the backups, and waits for ACKs before logging a commit message.
This is very similar to the previous solution, but it gives us two benefits over the previous approach:
- We can potentially handle more events in parallel; most of the transactions will not conflict with each other, and we can simply abort and retry the ones that do.
- We can now roll back operations. Suppose a network operator issues a policy change to the controller, but realizes that she made a mistake. No problem – she can simply roll back the previous transaction and start again where she began.
Compared to the first approach, this is a significant improvement! Each event is handled in isolation from the other events, so there’s need to reason about event interleavings; if a conflicting transaction was committed before we get to commit, just abort and retry!
Reorder events when no one will notice
It turns out that we can achieve even better throughput if we use a replication model called virtual synchrony. In short, virtual synchrony provides a library with three operations:
- join() a process group
- register() an event handler
- send() an atomic multicast message to the rest of your process group.
These primitives provide two crucial guarentees:
- Atomic multicast means that if any correct node gets the message, every live node will eventually get the message. That implies that if any live node ever gets the link failure notification, you can rest assure that one of your future masters will get it.
- The join() protocol ensures that every node always know who’s a member of its group, and that everyone has the same view of who is alive and who is not. Failures results in a group change, but everyone will agree on the order in which the failure occured.
With virtual synchrony, we no longer need a single master; atomic multicast means that there is a single order of events observed by all members of the group, regardless of who initiated the message. And with multiple masters, we aren’t constrained by the speed of a single node.
The virtual part of virtual synchrony is that when the library detects that two operations are not causally related to each other, it can reorder them in whatever way it believes most efficient. Since those operations aren’t causally related, we’re guaranteed that the final output won’t be noticeably different.
OK, let’s move on to the final three approaches, which take a different tack than the first four: “avoid having to reason about event ordering altogether”
Make yourself stateless
In a database, the “ground truth” is stored on disk. In a network, the “ground truth” is stored in the routing tables of the switches themselves. This implies that the controllers’ view of the network is just soft state; we can always recover it simply by querying the switches for their current configuration!
How does this observation relate to the Floodlight bug? Suppose we didn’t even attempt to keep the backup controllers in sync with the master. Instead, just have them recompute the entire network configuration whenever they realize they need to take over for the master. Their only job in the meantime is to monitor the liveness of the master!
Of course, the tradeoff here is that it may take significantly longer for the newly elected master to get up to speed.
We can apply the same trick to avoid race conditions between concurrent events at the master: instead of maintaining locks between threads, just restart computation of the entire network configuration whenever a new event comes in. Race conditions don’t happen if there is no shared state!
Incidentally, Google’s wide-area network controller is almost entirely stateless, presumably for many of the same reasons.
Force yourself to be stateless
In the spirit stateless computation, why not write your code in a language that doesn’t allow you to keep state at all? Programs written in declarative languages such as Overlog have no explicit ordering whatsoever. Programmers simply declare rules such as “If the switch has a link failure, then flush the routing entries that go over that link”, and the language runtime handles the order in which the computation is carried out.
With a declarative language, as the long as the same set of events is fed to the controller (regardless of their order), the same result will come out. This makes replication really easy: send inputs to all controllers, have each node compute the resulting configuration, and only allow the master node to send out commands to the switches once the computation has completed. The tradeoff is that without an explicit ordering. the performance of declarative languages is difficult to reason about.
Guarantee self-stabilization
The previous solutions were designed to always guarantee correct behavior despite failures of the other nodes. This final solution, my personal favorite, is much more optimistic.
The idea behind self-stabilizing algorithms is to have a provable guarantee that no matter what configuration the system starts in, and no matter what failures occur, all nodes will eventually stabilize to a configuration where safety properties are met. This eliminates the need to worry about correct initialization, or detect whether the algorithm has terminated. As a nice side benefit, self-stabilizing algorithms are usually considerably simpler than their order-aware counterparts.
What do self-stabilizing algorithms look like? Self-stabilizing algorithms are actually everywhere in networking – routing algorithms are the most canonical example.
How would a self-stabilizing algorithm help with the Floodlight bug? The answer really depends on what network invariants the control application needs to maintain. If it’s just to provide connectivity [7], we could simply run a traditional link-state algorithm: have each switch periodically send port status messages to the controllers, have the controllers compute shortest paths using Dijkstra’s, and have the master push the appropriate updates to the switches. Even if there are transient failures, we’re guaranteed that the network will eventually converge to a configuration with no loops and deadends.
Ultimately, the best replication choice depends on your workload and network policies. In any case, I hope this post has convinced you that there’s more than viable approach to handling concurrency!
Footnotes
[1] Note that this issue was originally discovered by the developers of Floodlight. (We don’t mean to pick on BigSwitch here; we chose this bug because it’s a great example of the difficulties that come up in distributed systems). For more information, see line 605 of Controller.java.
[2] This invariant is crucial to maintain. Think of the switches’ routing tables as shared variables between threads (controllers). We need to ensure mutual exclusion over those shared variables, otherwise we could end up with internally inconsistent routing tables.
[3] The Floodlight bug noted in [1] actually involves neglecting to clear the routing tables of newly connected switches, but the same flavor of race condition could occur for link failures. We chose to focus on link failures because they’re likely to occur much more often than switch connects.
[4] It’s possible in some cases to use a model checker to automatically find race conditions, but the runtime complexity is often intractable and very few systems do this in practice.
[5] There are actually a handful of ways to implement state machine replication. Ours depend on a concensus algorithm to choose the master, but you could also run the concensus algorithm itself to achieve replication. There are also cheaper algorithms such as reliable broadcast. You can also get significantly better read throughput with chain replication, which doesn’t require quorum for reads, but writes become more complicated.
[6] We still need to maintain the invariant that only the master modifies the the switch configurations. Nonetheless, with state machine replication the backup will always know what commands need to be sent to switches if and when it takes over for the master.
[7] Although if your goal is only to provide connectivity, it’s not clear why you’re using SDN in the first place.