I often overhear a recurring debate amongst researchers: is Academia a good place to build real software systems? By “real”, we typically mean “used”, particularly by people outside of academic circles.
There have certainly been some success stories. BSD, LLVM, Xen, and Spark come to mind.
Nonetheless, some argue that these success stories came about at a time when the surrounding software ecosystem was nascent enough for a small group of researchers to be able to make a substantial contribution, and that the ecosystem is normally at a point where researchers cannot easily contribute. Consider for example that BSD was initially released in 1977, when very few open source operating systems existed. Now we have Linux, which has almost 1400 active developers.
Is this line of reasoning correct? Is the heyday of Academic systems software over? Will it ever come again?
Without a doubt, building real software systems requires substantial (wo)manpower; no matter how great the idea is, implementing it will require raw effort.
This fact suggests an indirect way to evaluate our question. Let’s assume that (i) any given software developer can only produce a fixed (constant) amount of coding progress in a fixed timeframe and (ii) the maturity of the surrounding software ecosystem is proportional to collective effort put into it. We can then approximate an answer to our question by looking at the number of software developers in industry vs. the number of researchers over time.
It turns out that the Bureau of Labor Statistics publishes exactly the data we need for the United States. Here’s what I found:
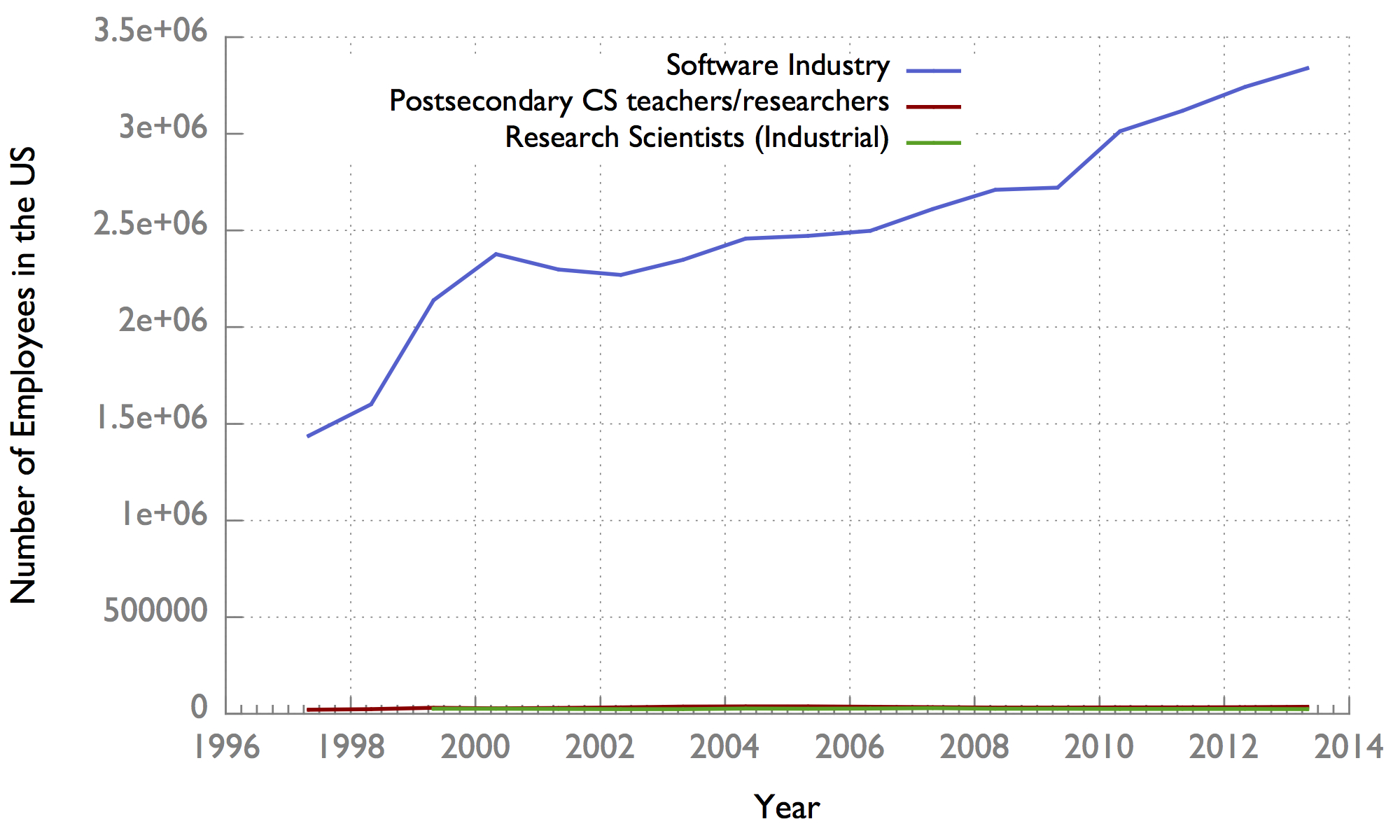
Hm. The first thing we notice is that it’s hard to even see the line for academic and industrial researchers. To give you a sense of where it’s at, the y-coordinate at May, 2013 for computer science teachers and professors is 35,770, two orders of magnitude smaller than the 3,339,440 total employees in the software industry at that time.
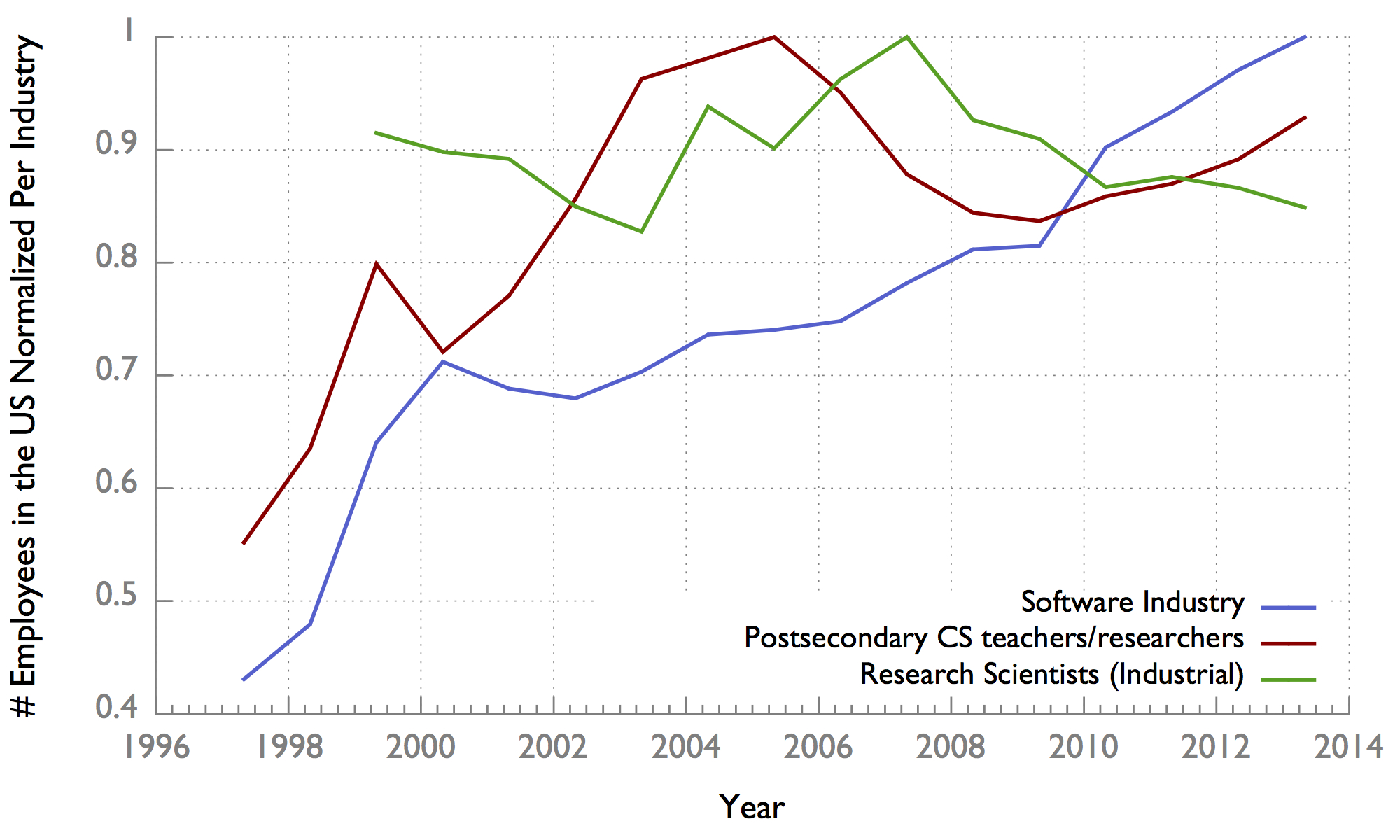
What we really care about though is the ratio of employees in industry to number of researchers:

In the last few years, both the software industry and Academia are growing at roughly the same rate, whereas researchers in industrial labs appear to be dropping off relative to the software industry. We can see this relative growth rate better by normalizing the datasets (dividing each datapoint by the maximum datapoint in its series – might be better to take the derivative, but I’m too lazy to figure out how to do that at the moment):
The data for the previous graphs only goes back to 1995. The Bureau of Labor Statistics also publishes coarser granularity going all the way to 1950 and beyond:
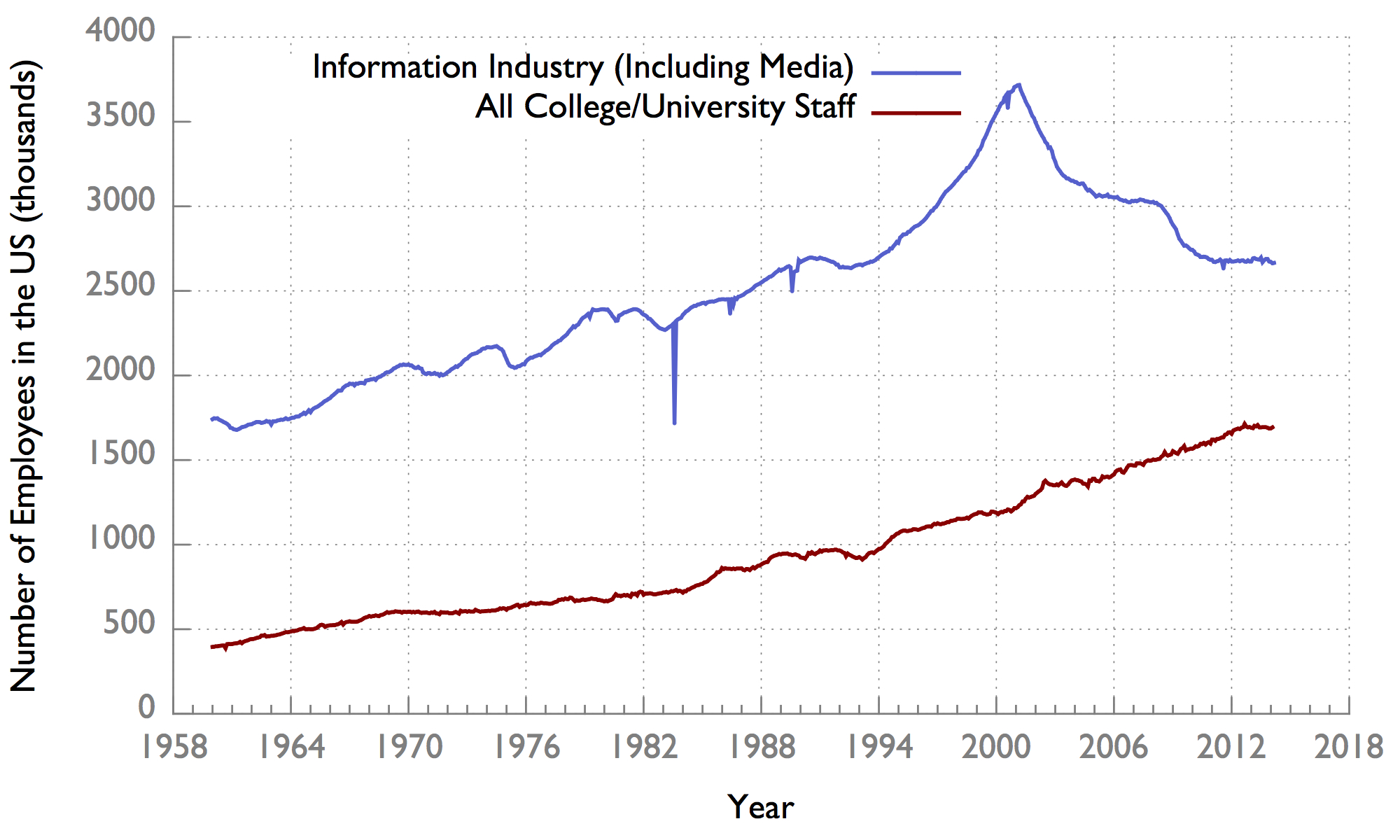
(See the hump around 2001?)
Not sure if this data actually answers our initial question, but I certainly found it insightful! If you’d like more details on how I did this analysis, or would like to play around with the data for yourself, see my code.